Connecting Node(s): Enterprise Integration Patterns
• • ☕️ 6 minute readWhen working on the backend developers often tend to face the problem of connecting different servers together. Often, devs tend to switch to a monolithic architecture, where they then expose certain modules to each other in order to facilitate the problem. Another way to connect different servers is by using RPC, which is short for remote procedure calls. RPC has its foundations in Distributed Systems, and is now modernized and used in many networking libraries that implement server-2-server communication. In this article we will focus on the second solution, namely messaging architectures, whereby we look for different solutions (specifically for Node.js backends). This is the introductory article of the Software Architecture series.
API Gateways
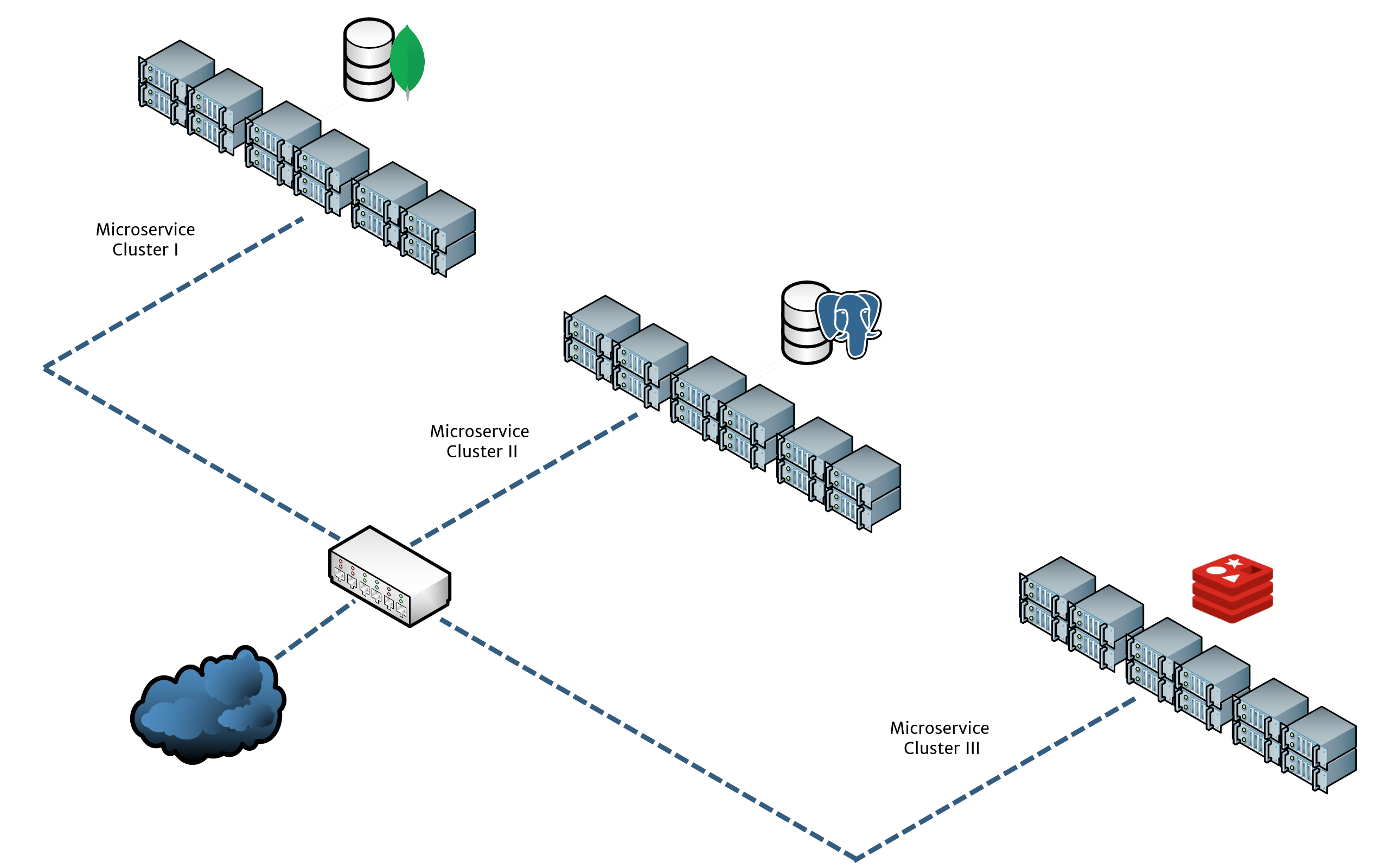
A first design that is commonly used in production is the API Gateway. It acts like a switch which resolves service requests by delegating these requests to the right server (the one which offers the service) and then passes the response back to where it came. Henceforth, it is a type of service which provides a shared layer and API for clients to communicate with internal services. The API Gateway can route messages, transform protocols, aggregate responses and implement shared logic like authentication and request-limiters.
The benefit of this setup is that facilitates flexibility and scalability, as different technologies can be used together. For example a GraphQL backend and a REST server can be properly put together serving request in a moments notice. An example setup is shown in the image below, whereby three microservice clusters are backed by different persistence layers (respectively MongoDB, Postgres and Redis). These clusters are then linked together through an API gateway, which is resembled as a switch.
As described in Microservice Patterns, there are several forces that stimulate the adoption of API Gateways:
- The granularity of APIs provided by microservices is often different than what a client needs. Microservices typically provide fine-grained APIs, which means that clients need to interact with multiple services.
- Different clients need different data.
- The number of service instances and their locations (host+port) changes dynamically.
- Partitioning into services can change over time and should be hidden from clients.
- Services might use a diverse set of protocols, some of which might not be web friendly.
There are multiple frameworks one could use to implement the concept, some of the more production ready frameworks are:
- https://www.express-gateway.io/
- https://www.apollographql.com/docs/apollo-server/api/apollo-gateway/
- https://konghq.com/
- https://www.krakend.io/
- https://hellofresh.gitbooks.io/janus/
- https://micro.mu/docs/api.html
One of the additional benefits is the possibility of smooth transition from monolith architecture to microservices, also called evolutionary design. In most of the cases rewriting your backend from scratch as a microservices architecture is not time efficient and costs hours of development time, therefore stalling the development and implementation of new and more important business features. The API Gateway approach can help you to “break down the monolith”. In this case, we can put an API Gateway in front of our monolith application, which acts as a proxy, and implement new functionalities as microservices and route new endpoints to the new services while we can serve old endpoints via monolith. Later we can also break down the monolith with moving existing functionalities into new services.
A good video that sums up this part:
Message Bus / Queue
Another solution which is favored when good performance and maximum scalability is preferred is the Message Bus architecture. A Message Bus is a combination of a common data model, a common command set (such as gRPC) and a messaging infrastructure to allow different systems to communicate through a shared set of interfaces. It is very similar to how the motherboard on your PC is physically constructed. It is an architecture that enables separate applications to work together, but in a decoupled fashion such that applications can be easily added or removed without affecting the others. An Enterprise Service Bus (ESB) builts on top of this architecture and focuses on connecting different applications with each other. Since messaging completely relies on the Message Bus it also makes for a convenient place to enforce security and compliance requirements, log events and even handle transaction performance monitoring. An ESB also provides load balancing in which multiple copies of a component can be instantiated to improve performance. When preferred, it can also often provide failover support should a component or its resources fail, hence increasing system reliability.
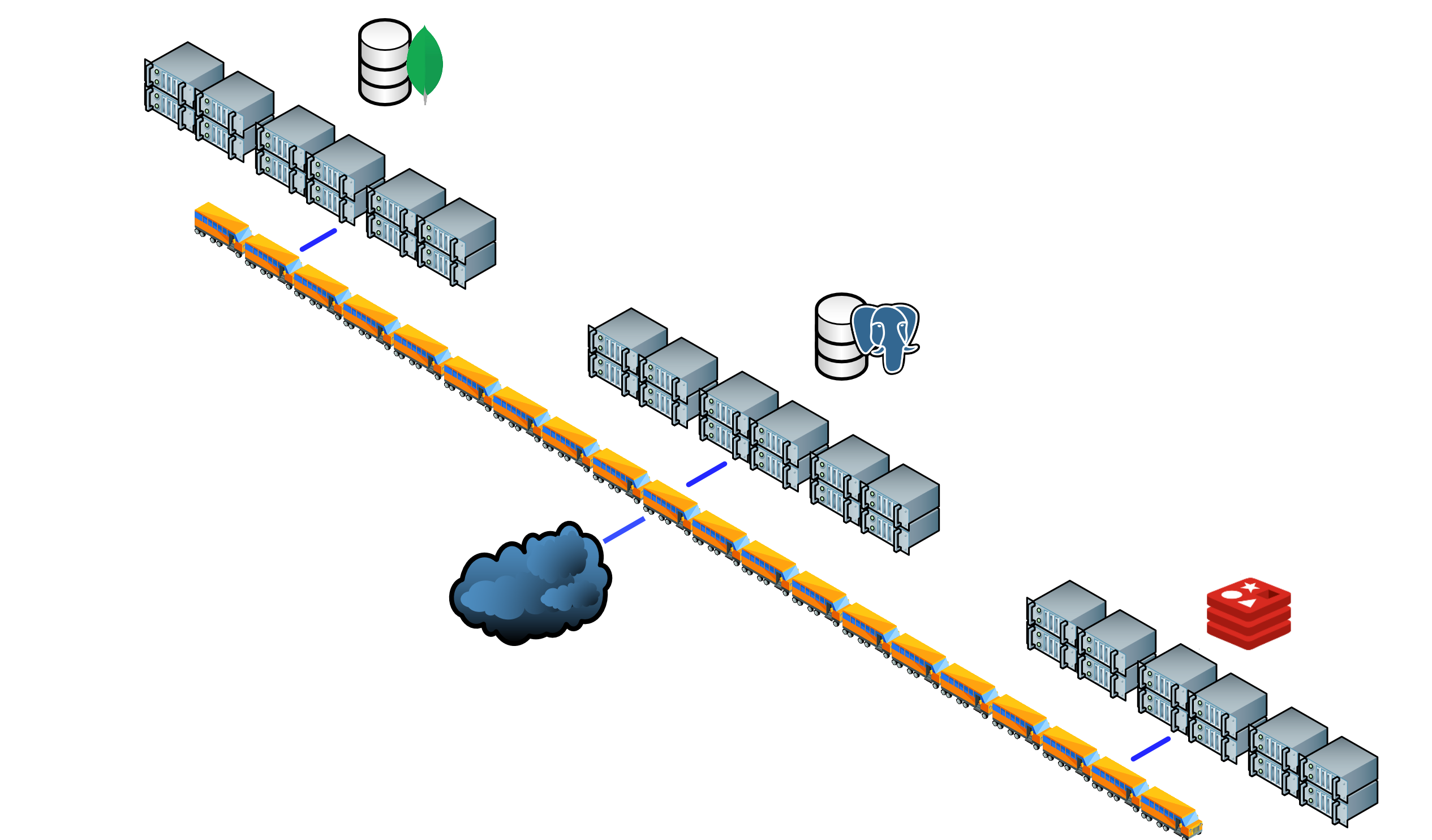
If you’re looking for a production ready framework that implements this pattern, you should look for:
- https://kubemq.io/
- https://activemq.apache.org/
- http://kafka.apache.org/
- https://www.rabbitmq.com/
- http://zeromq.org/
- An overview: https://taskqueues.com/
It is worth noting that many cloud service providers such as AWS, Azure, Google and IBM provide their own implementations. Developers should make a choice between keeping it provider-independent such as with ZeroMQ and Kafka, or choosing for a vendor lock-in which sometimes offers additional benefits such as increased reliability, less configuration effort needed, highly available/scalable.
Service Mesh
A service mesh is not a “mesh of services.” It is a mesh of API proxies that (micro)services can plug into to completely abstract away the network. It is a “dedicated infrastructure layer for making service-to-service communication safe, fast, and reliable”. A nice description from NGINX:
A service mesh ensures that communication among containerized and often ephemeral application infrastructure services is fast, reliable, and secure. The mesh provides critical capabilities including service discovery, load balancing, encryption, observability, traceability, authentication and authorization.
As described in Microservice Patterns, problems that push towards the adoption of a Service Mesh are:
- Externalized configuration - includes credentials, and network locations of external services such as databases and message brokers
- Logging - configuring of a logging framework such as log4j or logback
- Health checks - a url that a monitoring service can “ping” to determine the health of the application
- Metrics - measurements that provide insight into what the application is doing and how it is performing
- Distributed tracing - instrument services with code that assigns each external request an unique identifier that is passed between services.
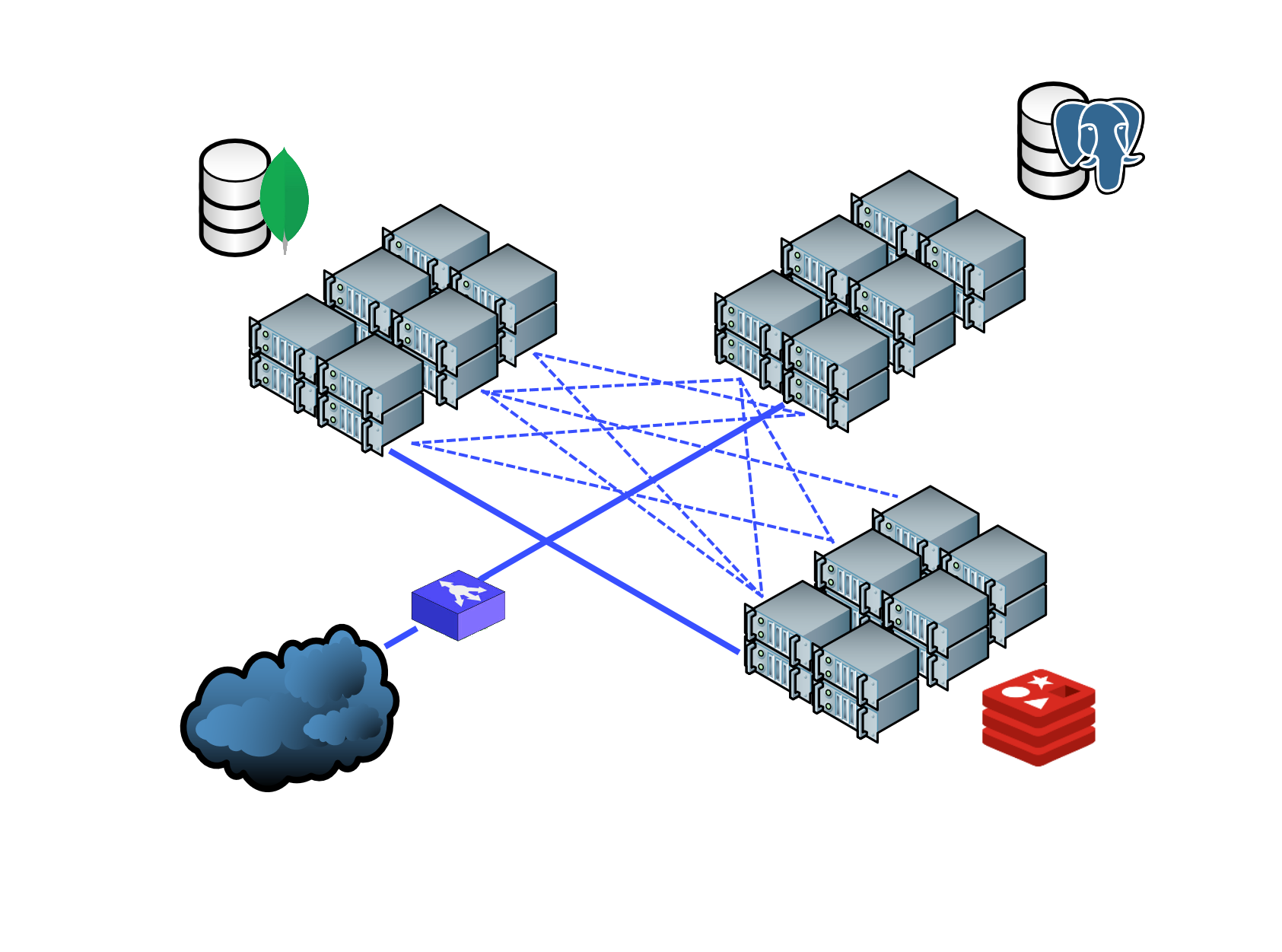
In a typical service mesh, service deployments are modified to include a dedicated “sidecar” proxy. Instead of calling other services directly over the network, services call their local sidecar, which acts as a proxy and in turn encapsulates the complexities of the service-to-service exchange. The set of APIs used to control proxy behavior across the service mesh is referred to as its control plane. The control plane is where users specify policies and configure the data plane, which is the interconnected set of proxies in the mesh.
Production ready frameworks that are often used are:
- https://www.envoyproxy.io/
- https://linkerd.io/
- https://istio.io/
- https://www.consul.io/
- One mesh to rule them all: https://supergloo.solo.io
It is worth noting that a Service Mesh incurs a steep learning curve, as containerization of the servers is required (Docker, Kubernetes). This is in contrast with the other solutions that are more easily integrated in the existing codebase. I advice to make decisions on which pattern to use based on the business needs.
More in depth articles with some code samples regarding API-Gateways, Message Queues & Service Meshes will follow.